TildeOpen LLM: suverēns Eiropas daudzvalodu MI
Atvērtā pirmkoda, pamata LVM (lielais valodas modelis) Eiropas valodām – drošs, pielāgojams un gatavs darbam valdībās, iestādēs un uzņēmumos.
2024. gada jūnijs
Tilde uzvar AI Grand Challenge
2024. gada septembris
Piekļuve LUMI
superdatoram
2025. gada marts
Sākas
modeļa apmācība
2025. gada septembris
Modelis pieejams Hugging Face
2026. gada februāris
TildeOpen ir pieejams
Tildes mašīntulkošanā

Mūsu valoda ir pelnījusi labāku MI
Lielākā daļa MI modeļu ir veidoti pasaules lielākajām valodām - un vairāk nekā 90% LVM mācību datu ir angļu valodā. Tas nozīmē, ka baltu, slāvu un citas Eiropas valodas atpaliek, kas noved pie zemākas precizitātes, vājākas kultūras izpratnes un ierobežotas piekļuves kvalitatīviem MI rīkiem.
Tāpēc mēs izstrādājām TildeOpen LLM - atvērtā pirmkoda lielo valodas pamatmodeli ar vairāk nekā 30 miljardiem parametru, kas izveidots visu Eiropas valodu atbalstam. Pielāgojiet modeli savām vajadzībām un droši izvietojiet - lokāli vai mākonī -, lai veidotu uzticamu MI, kas tiešām runā jūsu valodā.
TildeOpen LLM ir Eiropas atbilde uz nepieciešamību pēc suverēna LLM, kas labāk atbalsta Baltijas, slāvu un citas Eiropas valodas papildus tiem MI risinājumiem, kuru prioritāte ir angļu valoda.

Kāpēc TildeOpen?
- Pielāgojams, izmantojot savus datus
- Drošs un pilnībā kontrolējams
- Izvietojams lokāli vai mākonī
- Iespēja integrēt esošās sistēmās un darbplūsmās
- Būvēts kā pamats moderniem MI risinājumiem

MI pamats, kam var uzticēties
TildeOpen ir vairāk nekā tehnoloģisks sasniegums. Tas ir atvērtā pirmkoda pamats pielāgotam mākslīgajam intelektam, kurš var sniegt labumu vairāk nekā 155 miljoniem eiropiešu.
Pielāgoti MI risinājumi
Pielāgojiet TildeOpen savai nozarei, datiem un darbplūsmām - no virtuālajiem palīgiem līdz drošai tulkošanai, runas tehnoloģijām un daudz kam citam.
Valsts valodas modeļa izstrāde valdībām
Veidojiet iekļaujošus valodas modeļus, kas kalpo sabiedrības vajadzībām, veicina digitālo suverenitāti un atbalsta visas oficiālās ES valodas.
Uzticama veiktspēja visās fokusa valodās
TildeOpen publiskajos testos konsekventi uzrāda augstu valodas precizitātes un izpratnes līmeni
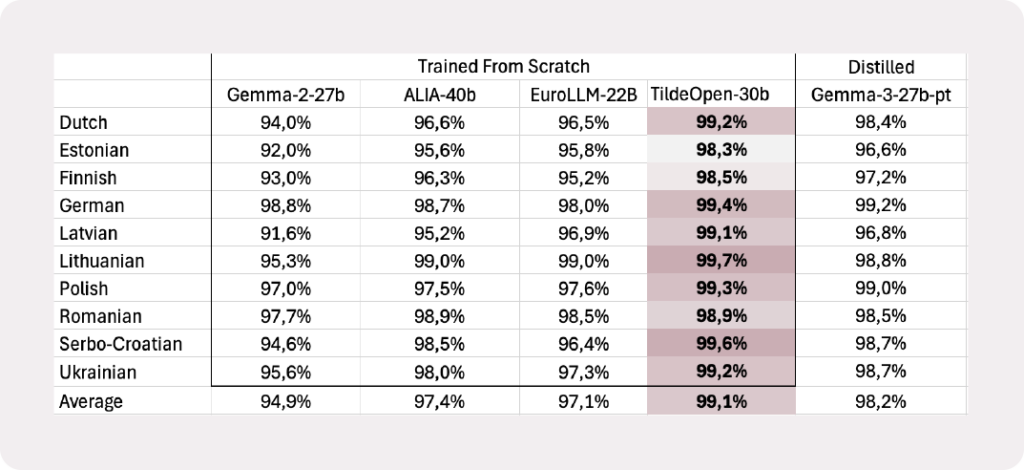
TildeOpen uzrāda labus rezultātus MultiBLiMP testā, kas mēra modeļa spēju atšķirt gramatiski pareizus teikumus no gramatiski nepareiziem. Zemāks kļūdu īpatsvars liecina par labāku gramatikas modelēšanu un uzticamāku teksta ģenerēšanu. Apskatiet pilnus testa rezultātus šeit.
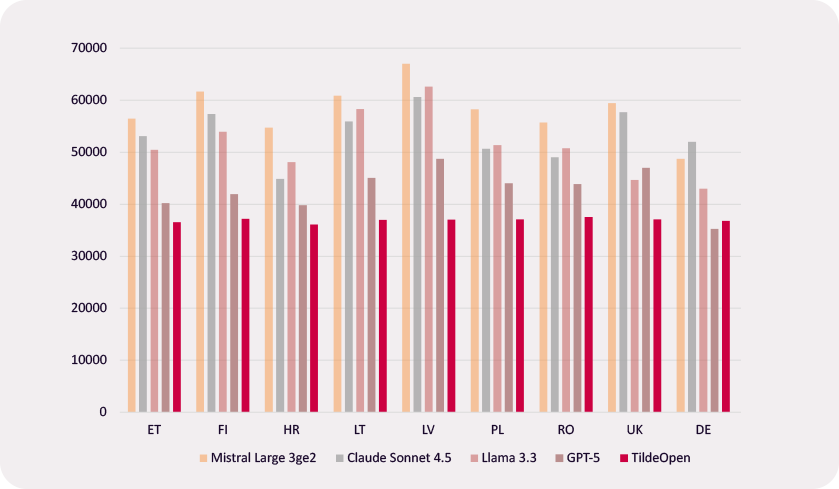
TildeOpen nodrošina augstāku efektivitāti morfoloģiski bagātās Eiropas valodās, pateicoties īpaši tām pielāgotam tokenizatoram un arhitektūrai. Salīdzinot ar LLaMA-3, tas ir par 41% efektīvāks latviešu valodā, par 37% lietuviešu valodā, par 31% somu valodā un par 28% igauņu un poļu valodā, vienlaikus pārspējot arī GPT un Mistral modeļus. Tas nodrošina ātrāku teksta ģenerēšanu lokālas izvietošanas gadījumos un tādējādi zemākas ekspluatācijas izmaksas par to pašu datu apjomu. Apskatiet pilnus testa rezultātus šeit.
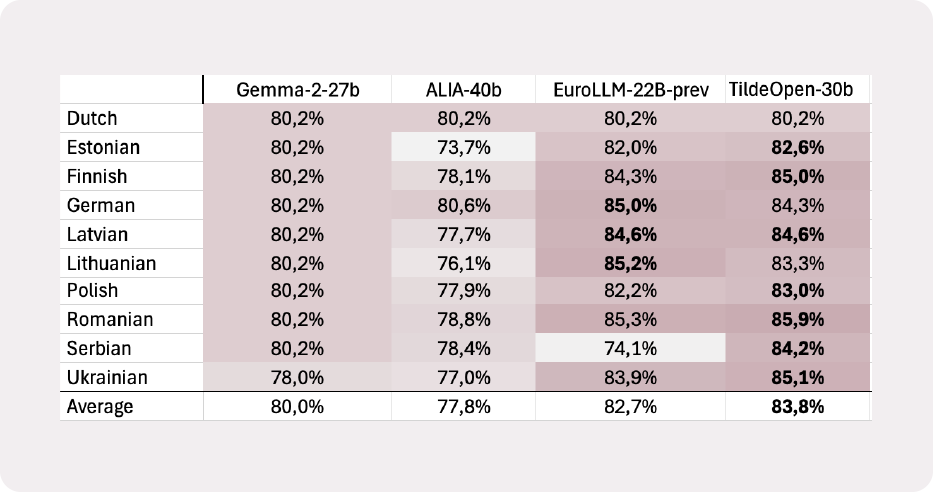
TildeOpen-30B sasniedz nozares līmeņa labāko rezultātu Belebele lasīšanas izpratnes testā, sasniedzot vidējo precizitāti 84,7%. Modelis pārspēj citus lokāli izvietojamus modeļus, piemēram, Gemma-27B, ALIA-40B un EuroLLM-22B. Apskatiet pilnus testa rezultātus šeit.
Superdatoru jauda, Eiropas atbalsts
TildeOpen attīstību atbalsta Eiropas Komisija, un to nodrošina Kopuzņēmuma EuroHPC augstākā līmeņa superdatori — LUMI un Jupiters. Uzvarot Large AI Grand Challenge, mums ir piešķirti 2 miljoni GPU stundu darbam ar LUMI, lai realizētu šo vērienīgo projektu.

Sniedziet savu ieguldījumu daudzvalodu nākotnē

Modelis pieejams Hugging Face
Dodieties uz Hugging Face, lai izpētītu TildeOpen-30b un piekļūtu pilnajai tehniskajai dokumentācijai.






Mūsu solījums
Atvērta sadarbība
Valdības var izmantot TildeOpen, lai izveidotu pielāgotus valodas modeļus, kas uzlabo piekļuvi sabiedriskajiem pakalpojumiem visiem iedzīvotājiem.
Drošība un uzticamība
Mēs nepārtraukti strādājam, lai samazinātu kaitīga vai neprecīza satura daudzumu TildeOpen, padarot to par uzticamu risinājumu publiskā sektora vajadzībām.
Brīva piekļuve
TildeOpen būs pieejams gan komerciālai, gan nekomerciālai lietošanai saskaņā ar liberālu licenci, kas ir publicēta platformā Hugging Face un ELRC-SHARE.
Zināšanu apmaiņa
Mēs ticam atvērtai sadarbībai un zināšanu apmaiņai, tāpēc aicinām partnerus iesaistīties TildeOpen attīstībā sabiedrības kopējam labumam.
Bieži uzdotie jautājumi
Kas ir TildeOpen LVM?
TildeOpen LLM ir atvērtā pirmkoda daudzvalodu LLM, kas izstrādāts Eiropas valodām. Tā ir suverēna MI pamatmodeļa sistēma ar vairāk nekā 30 miljardiem parametru, kas izstrādāta, lai atbalstītu Baltijas, Austrumeiropas un citas Eiropas valodas līdzās lielākajām pasaules valodām. Modeli TildeOpen var pielāgot, un izvietot lokāli vai mākonī, un to var izmantot gan komerciāliem, gan nekomerciāliem mērķiem saskaņā ar atļaujošu licenci.
Kāpēc lielajos valodas modeļos ir svarīga valodu vienlīdzība?
Šī nelīdzsvarotība ietekmē efektivitāti un izmaksas. Piemēram, ir nepieciešamas garākas secības, lai kodētu tādu pašu informācijas apjomu valodās ar zemākiem resursiem nekā angļu valodā, tādējādi padarot modeļus mazāk efektīvus un dārgākus palaišanai. Turklāt šo modeļu angliskums var radīt nevēlamus kultūras aizspriedumus. TildeOpen tiks apmācīts, lai nodrošinātu taisnīgumu visās atbalstītajās valodās.
Kādās valodās TildeOpen projekts koncentrējas?
Kas ir LUMI superdators?
Kas ir Large AI Grand Challenge?
Kas ir Tilde?
Eiropas Komisijas finansētā konkursa „Large AI Grand Challenge“ mērķis ir paplašināt Eiropas sasniegumus mākslīgā intelekta jomā, izmantojot liela mēroga mākslīgā intelekta modeļu potenciālu. Konkursā piedalījās inovatīvi start-up uzņēmumi un MVU, kuriem ir tehniskās iespējas izstrādāt mākslīgā intelekta modeļus, kas veicina Eiropas konkurētspēju ģeneratīvā mākslīgā intelekta jomā. Eiropas Komisija izziņoja konkursa „Large AI Grand Challenge“ uzvarētājus. Četri inovatīvi Eiropas mākslīgā intelekta uzņēmumi, tostarp „Tilde“, sadalīja 1 miljonu eiro lielu balvu un 8 miljonus GPU stundu, lai stiprinātu Eiropas vadošo lomu mākslīgā intelekta attīstībā.
Jaunākās Tildes pētniecības un izstrādes aktivitātes ir vērstas uz fundamentāliem lieliem valodas modeļiem (LLM), LLM precizēšana lejupstraumes lietojumiem, un instrukcijām pielāgotu lielo valodas modeļu integrācija dabiskās valodas apstrādes lietojumprogrammās (piemēram, mašīntulkošana, virtuālie asistenti, izguves pastiprinātas ģenerēšanas sistēmas, runas apstrāde, kopsavilkums, u. c.).